PE 전체구조 이해하기
PE 파일 구조를 처음 봤을때 느낌은 생각보다 너무 많아보여 이해하기가 쉽지 않았다.
PEview로 파일을 열어 보면 위쪽에 뭔가 헤더들이 보이고 그 아래로 섹션 목록이 쭉 이어지는데
도대체 어디부터 어디까지가 무엇을 의미하는지 한 번에 잡히지는 않았다.
그래서 이번에는 내가 PEview와 HxD를 보면서 이해한 흐름을 기준으로 정리해 보려고한다.
먼저 전체 레이아웃부터 눈에 익혀 두는 편이 훨씬 이해가 편했다.
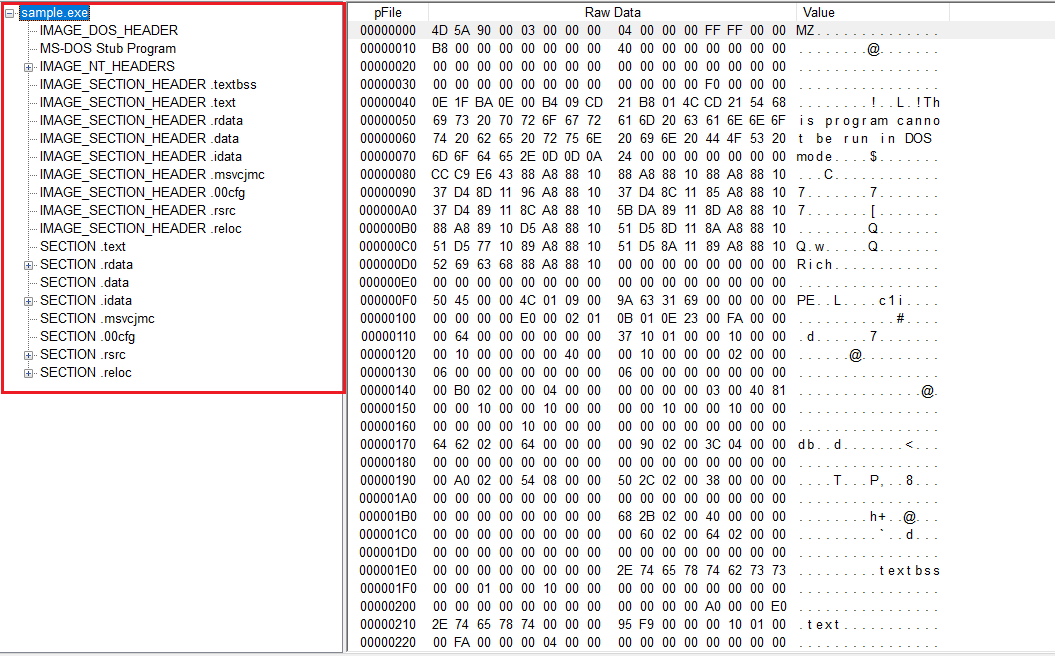 PE layout
PE layout
이 사진만 봐도 위에서부터 DOS 헤더가 나오고 그 뒤에 NT 헤더와 Section 헤더가 붙고
마지막에 각 섹션의 실제 데이터가 파일 뒤쪽을 채우고 있다는 흐름이 어느 정도 보인다.
DOS Header & DOS Stub
PE 파일의 맨 앞에는 DOS 헤더가 들어 있다.
이 부분은 원래 MS DOS 실행 파일 형식에서 이어져 내려온 헤더라서 지금 기준으로 보면 역사적인 이유가 조금 더 큰 영역이기도 하다.
구조체만 봐도 IMAGE_DOS_HEADER 구조체가 꽤 길게 정의되어 있다.
실제로 분석하면서 계속 보게 되는 필드는 많지 않았다.
나는 e_magic과 e_lfanew 두 가지만 제대로 이해해도 DOS 헤더 쪽은 크게 어렵지 않다고 느꼈다.
전체 구조체를 다 작성할까 하다가 그냥 중요한 필드들만 빼서 작성하기로 했다.
typedef struct _IMAGE_DOS_HEADER {
WORD e_magic;
LONG e_lfanew;
} IMAGE_DOS_HEADER;
PEview로 보면 파일 맨 앞에서 e_magic 값이 바로 눈에 들어온다.
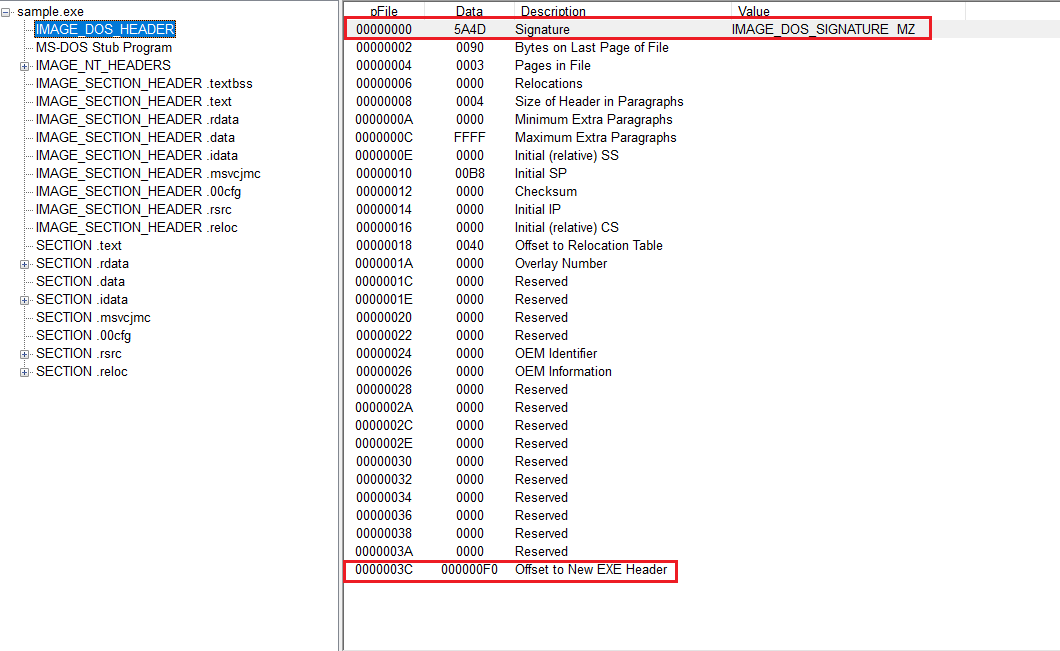 PEview-IMAGE_DOS_HEADER
PEview-IMAGE_DOS_HEADER
e_magic에는 MZ라는 값이 들어 있다.
이 값이 도스 시절 실행 파일 시그니처였고 지금도 그대로 유지되고 있다.
운영체제는 이 값을 보고 일단 이 파일이 실행 파일 형식을 따르는지부터 확인하게 된다.
e_lfanew는 NT 헤더가 파일 어디에 있는지 알려 주는 오프셋 역할을 한다.
HxD로 같은 파일을 열어 보면 이 두 값이 실제로 어떤 위치에 놓여 있는지 더 직접적으로 보인다.
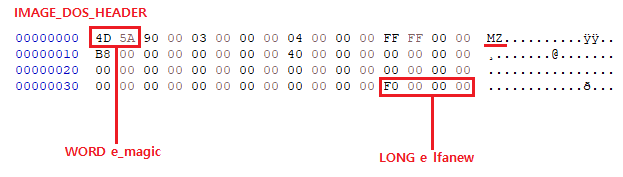 HxD-IMAGE_DOS_HEADER
HxD-IMAGE_DOS_HEADER
맨 앞쪽에 4D 5A 바이트 패턴이 보이는데 이것은 리틀엔디언 방식으로 표기되어 있고 MZ에 해당하는 부분이다.
조금 아래쪽에 보게되면 있는 값이 e_lfanew 값이다.
이 값이 가리키는 위치로 가보면 NT 헤더의 시작 지점이라는 것을 알게된다.
DOS 헤더 바로 뒤에는 DOS Stub이 따라온다.
이 영역에는 This program cannot be run in DOS mode 같은 문구가 들어 있다 .
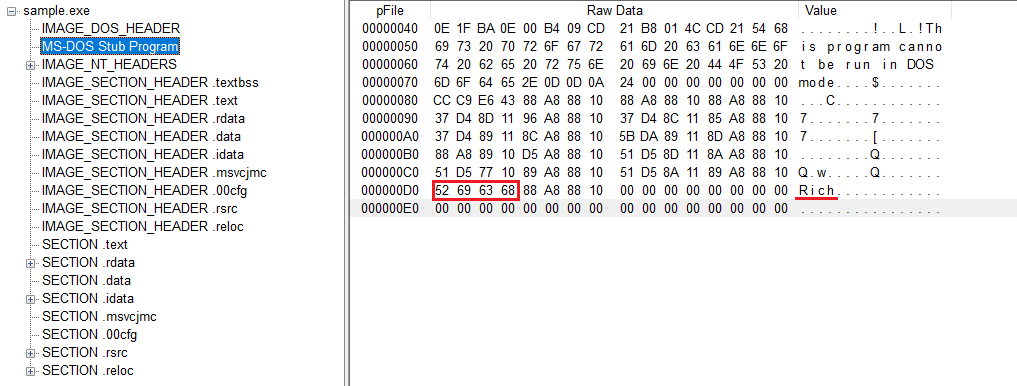 MS-DOS Stub Program
MS-DOS Stub Program
예전에는 도스 환경에서 이 파일을 실행했을 때 이런 메시지를 보여 주는 역할을 했지만 지금 기준에서는 영향력이 없는것 같아 보인다.
또한 저 문구가 끝난 후 Rich Header가 존재하는데 정확한 정보는 없지만 알려진 바로는
프로그램을 빌드한 컴파일러에 대한 정보, 실행파일이 생성된 환경 등이 포함되어 있는것 같다.
악성코드를 분석할때 참고용으로 활용이 되는것 같지만 PE 구조를 처음 공부할 때는 DOS Stub 내부 구조까지 깊게 파기보다는 DOS 헤더 뒤쪽에 이런 영역이 하나 있고 그 뒤부터 NT 헤더가 나온다는 정도만 잡고 넘어가는 편이 편했다.
IMAGE_NT_HEADERS
DOS 헤더의 e_lfanew가 가리키는 위치에는 NT 헤더가 있다.
PE 구조를 이해할 때 가장 핵심이 되는 부분이라 여기서부터는 조금 더 집중하게 되었다.
MSDN :IMAGE_NT_HEADERS
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32;
NT 헤더는 3가지로 분류된다.
Signature가 있고 IMAGE_FILE_HEADER와 IMAGE_OPTIONAL_HEADER 이다.
HxD로 전체 NT 헤더 영역을 보면 이 세 부분이 연속된 하나의 블록으로 붙어 있는 모습이 보인다.
 NT_HEADER DUMP
NT_HEADER DUMP
이제 각각이 어떤 역할을 하는지만 가볍게 짚고 넘어가 보면 구조가 훨씬 자연스럽게 이어진다.
NT Signature
NT 시그니처는 PE 파일임을 다시 한 번 확인하는 역할을 한다.
텍스트로 쓰면 PE와 널 문자 둘이 붙어 있는 형태다.
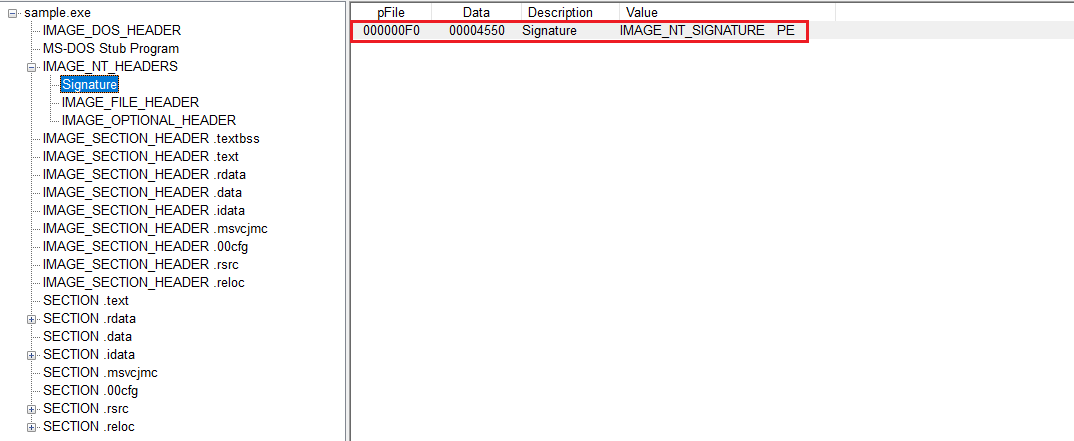 NT_Signature
NT_Signature
DOS 헤더에서 MZ로 한 번 검사를 했고 여기서 다시 PE 시그니처로 형식을 한 번 더 확인하는 느낌으로 보면 이해가 쉽다.
FileHeader
IMAGE_FILE_HEADER에는 아키텍처 정보와 섹션 개수 그리고 이 파일의 특성을 나타내는 값들이 들어 있다.
MSDN :IMAGE_FILE_HEADER
구조체 전체는 길지만 실제로 계속 보게 된 필드는 세 개였다.
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
WORD Characteristics;
} IMAGE_FILE_HEADER;
PEview에서 이 부분만 따로 보면 어떤 아키텍처용 실행 파일인지와 섹션 개수 그리고 파일 특성이 바로 눈에 들어온다.
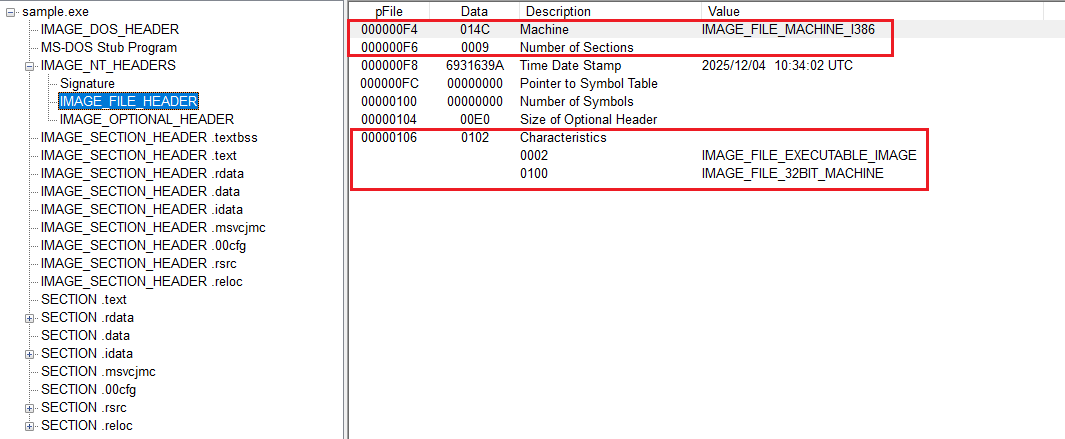 NT_File_Header
NT_File_Header
Machine은 이 실행 파일이 어떤 환경을 대상으로 빌드되었는지를 나타낸다.
NumberOfSections는 이 파일 안에 섹션이 몇 개 있는지를 알려 준다.
Characteristics에는 이 실행 파일이 어떤 성격을 가진 이미지인지 비트 플래그로 표현되어 있다.
OptionalHeader
이름은 OptionalHeader이지만 실제로 분석하면서 가장 많이 신경 쓰게 된 부분이 바로 이 영역이었다.
프로그램이 메모리에 로드될 때 필요한 정보들이 거의 다 OptionalHeader에 들어 있기 때문에
결국 이 구조를 어느 정도 편하게 읽을 수 있어야 전체 흐름이 잡힌다는 느낌이 들었다.
MSDN :IMAGE_OPTIONAL_HEADER32
OptionalHeader의 전체 구조체는 너무 많아서 나는 처음부터 전부 외우려고 하기보다는 실제로 자주 보는 필드들 위주로 정리했다.
typedef struct _IMAGE_OPTIONAL_HEADER32 {
WORD Magic;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD Subsystem;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[16];
} IMAGE_OPTIONAL_HEADER32;
PEview에서 OptionalHeader 부분을 보게 되면 얼마나 많은 멤버들이 있는지 알수 있다.
하지만 모든 것들을 바로 외우는것은 불가능하다 생각했기에 중요한 부분만 파악해보도록 하였다.
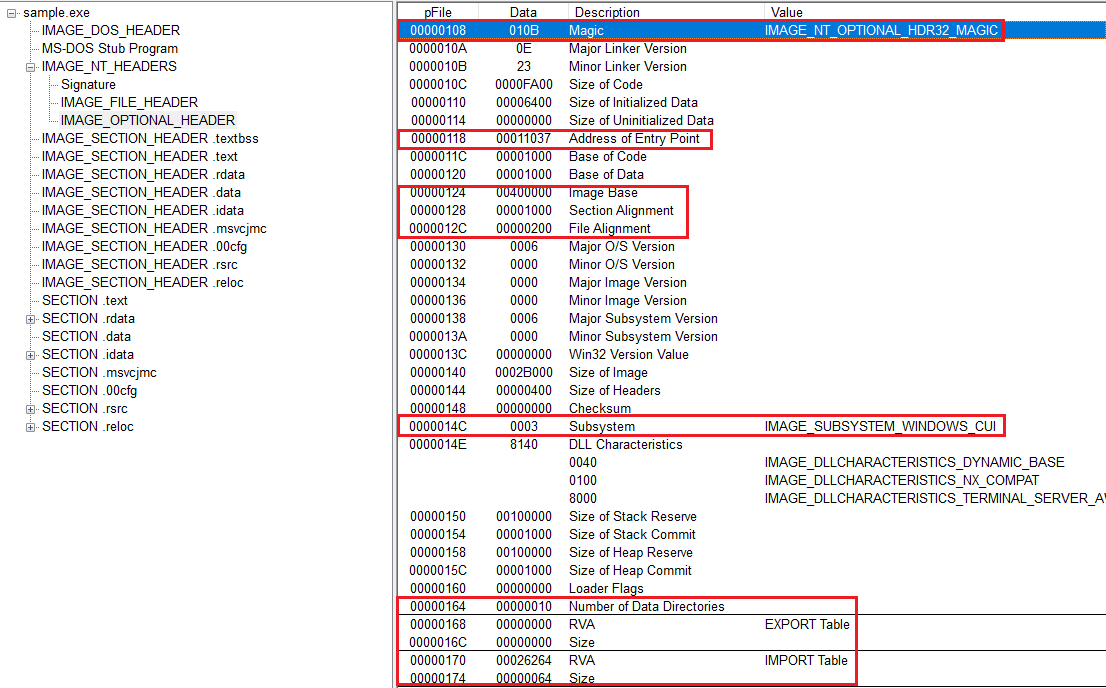 NT_Optional_Header
NT_Optional_Header
Magic 값은 이 실행 파일이 32비트 파일인지 64비트 파일인지 구분할수 있게 해준다.
AddressOfEntryPoint는 코드가 실제로 실행을 시작하는 위치를 나타내는 값이다.
값 자체는 RVA로 표현되지만 이번 글에서는 RVA 계산을 깊게 다루지는 않고
단순히 실행 진입점을 가리키는 논리적 위치 정도로만 보았다.
ImageBase는 이 실행 파일이 메모리에 기본적으로 로드될 시작 주소를 의미한다.
하지만 실제 실행 시에는 ASLR 이라는 기능 때문에 위치가 바뀔 수도 있지만
정적분석할 때 기준이 되는 값이라 생각하는 필드였다.
SectionAlignment와 FileAlignment는 메모리와 파일에서 섹션이 어떤 간격으로 정렬되는지 알려 준다.
이 값들은 나중에 RVA와 파일 오프셋 사이를 오갈 때 핵심이 되는 값인데
그 부분은 다른 글에서 RVA와 RAW 변환을 정리할 계획이다.
Subsystem은 이 실행 파일이 어떤 환경에서 돌아가는지를 나타낸다.
콘솔 프로그램인지 윈도우 GUI 프로그램인지 같은 정보가 들어 있다.
마지막으로 NumberOfRvaAndSizes와 DataDirectory 배열이 있다.
여기에는 Export Import Resource TLS 같은 중요한 디렉터리 정보들이 차례대로 들어 있다.
이 부분에 대해선 아직까지도 완벽하게 이해를 하지 못해 나중에 따로 공부할 예정이다.
OptionalHeader는 처음에는 필드가 너무 많아서 부담스럽게 느껴졌는데 실제로 분석할 때 계속 보게 되는 값은 생각보다 적었다.
그래서 중요한 필드 몇 개를 먼저 익히고 나머지는 필요할 때마다 MSDN을 참고하는 방식이 내 기준에서는 가장 현실적인 공부 순서였다.
IMAGE_SECTION_HEADER
NT 헤더가 끝나면 그 뒤에는 Section 헤더들이 연달아 붙어 있다.
개수는 앞에서 본 NumberOfSections 값과 정확히 일치한다.
Section 헤더는 각 섹션이 어떤 이름을 가지고 있는지 파일과 메모리에서 어디에 위치하는지
그리고 어떤 속성을 가지는지에 대한 정보를 담고 있다.
MSDN :IMAGE_SECTION_HEADER
구조체 전체를 보면 필드가 여러개 있지만 실제로 계속 보게 된 값은 아래 몇 가지였다.
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD Characteristics;
} IMAGE_SECTION_HEADER;
여러개의 섹션이 있지만 .text 섹션을 기준으로 확인해보았다.
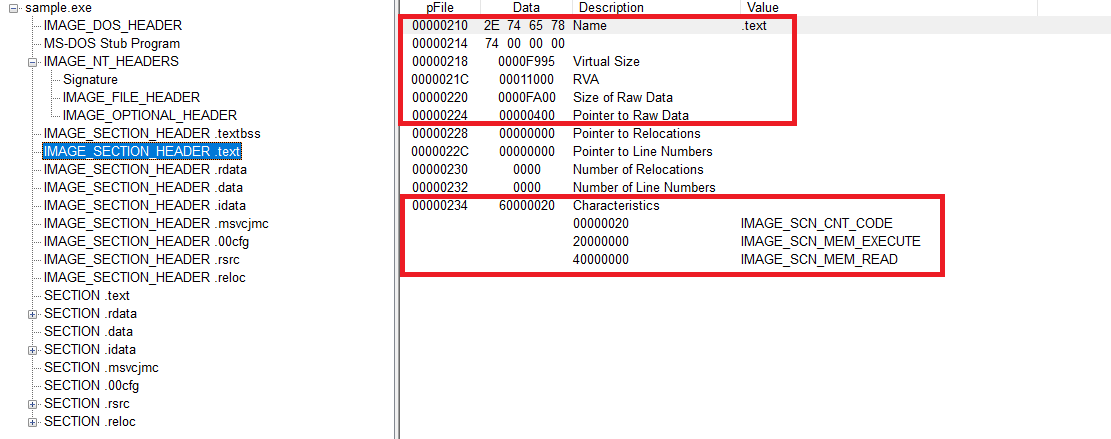 Section Header
Section Header
Name에는 섹션 이름이 들어 있다.
.text .rdata .data 같은 이름들이 여기에 들어가며 대략 어떤 용도의 섹션인지 감이 온다.
VirtualSize는 이 섹션이 메모리에서 실제로 차지하는 크기를 나타낸다.
VirtualAddress는 이 섹션이 ImageBase 기준으로 어느 위치에 매핑되는지를 나타내는 값이다.
이 값 역시 RVA로 표현되지만 자세한 계산은 RVA 글에서 다루기로 하고
지금은 섹션이 메모리에서 시작하는 지점을 논리적으로 나타내는 값 정도로 생각하면 될것같다.
SizeOfRawData는 이 섹션이 파일에서 차지하는 실제 크기다.
PointerToRawData는 이 섹션 데이터가 파일시점에서 어디에서 시작되는지를 알려 준다.
나중에 RVA와 파일 오프셋을 서로 변환할 때는
VirtualAddress와 PointerToRawData 그리고 정렬 정보들을 함께 사용하게 되는데
지금 단계에서는 Section 헤더가 파일 위치와 메모리 위치를 연결해 주는거라고 생각하면 된다.
Characteristics에는 이 섹션이 어떤 속성을 가지는지 비트 플래그로 표현되어 있다.
실행 권한이 있는지 쓰기 가능한지 같은 정보들이 이 값 하나에 묶여 있다.
Section body
지금까지는 헤더들만 계속 봤는데 실제 코드와 데이터는 Section 바디에 들어 있다.
각 섹션의 몸통 부분은 Section 헤더에서 본 PointerToRawData와 SizeOfRawData를 기준으로 파일 뒤쪽에 배치되어 있다.
여기서는 대표적인 세 가지 섹션만 가볍게 정리했다.
.text 섹션에는 실행 가능한 코드가 들어 있다. 프로그램의 함수와 명령들이 이 영역에 몰려 있고 보통 실행 권한과 읽기 권한이 있고 쓰기 권한은 없다.
.rdata 섹션에는 읽기 전용 데이터가 들어 있는 경우가 많았다.
상수 문자열이나 상수 테이블 그리고 바뀌면 안 되는 데이터들이 여기로 들어온다.
.data 섹션에는 초기값이 설정된 전역 변수와 정적 변수가 배치된다.
프로그램이 시작될 때 이미 값이 들어 있는 상태로 메모리에 올라가고 실행 도중 값이 바뀔 수 있는 데이터들이 이 영역에 모여 있다.
마무리
이 내용을 이해하고 작성하는것만 1주 이상 시간이 넘게 걸리는것 같다.
아직까지도 완벽하게 이해했다기 보다는 하나의 Big Picture를 그리기 위한 시도인것 같다.
PEview로 전체 레이아웃을 보고 DOS 헤더에서 MZ와 e_lfanew를 확인하고
NT 헤더에서 Signature, FileHeader, OptionalHeader를 하나씩 뜯어 보고
Section 헤더에서 이름과 메모리 위치, 파일 위치 그리고 속성을 같이 보면서 이해한것 같다.
이제는 PE 파일이 나름 잘 설계된 구조라는 느낌이 조금씩 들기 시작했다.
이번 글에서는 의도적으로 RVA와 RAW 변환 같은 계산은 다루지 않았다.
그것 조차 포함하려니 너무 많은 내용이라 혼동도 오는것 같고 나눠 이야기하는게 더 좋아보여서이다.
OptionalHeader의 ImageBase나 AddressOfEntryPoint,
Section 헤더의 VirtualAddress 같은 값이 전부 RVA 중심으로 되어 있어서
이 부분까지 이해하려면 너무 많은 이야기를 해야 하기 때문이다.
이 구조가 머릿속에 어느 정도 자리 잡고 나면
PE 파일을 열었을 때 눈에 들어오는 정보들이 훨씬 친숙하게 느껴질 거라고 생각한다.