문자 인코딩과 WinAPI A/W 구조 이해하기
문자열과 관련된 구조를 다시 살펴보면, 처음에는 단순히 문자 크기만 다르다고 생각했던 부분들이
실제로는 운영체제의 흐름과 API 구조 전체에 얽혀 있다는 걸 자연스럽게 느끼게 된다.
Win32를 공부하며 계속 부딪히는 것도 결국 이 흐름이었던것 같다.
아래는 내가 공부했던 내용들을 정리하여 작성한 글이다.
ASCII에서 ANSI, 그리고 유니코드 흐름
처음 프로그램에서 문자를 다루기 시작하면 자연스럽게 ASCII가 떠오른다.
영어 알파벳을 표현하는 데에는 충분했지만, 전 세계 언어를 담기에는 구조적으로 부족했다.
이 틀을 조금 더 확장하려고 각 국가마다 ANSI 코드 페이지를 만들기 시작했는데 그 순간부터 같은 숫자 값이 환경에 따라 전혀 다른 문자로 보이는 일이 생겼다.
Windows 역시 오래도록 ANSI 기반으로 동작했기 때문에 char 하나로 문자를 표현하고 코드 페이지에 맞춰 해석하는 구조가 기본이었다.
그 과정에서 MBCS가 등장했고, 한 글자가 1바이트가 되기도 하고 2바이트가 되기도 하는 유연하지만 계산하기에는 까다로운 구조를 만들어냈다.
이런 흐름을 지나며 결국 언어마다 서로 다른 규칙을 유지하는 방식이 유지될 수 없다는 결론에 닿았고, 전 세계 문자를 하나로 통합하려는 과정속 만들어진게 바로 유니코드이다.
Windows는 왜 UTF-16을 기반으로 했을까
Windows 내부를 보면 문자열이 대부분 2바이트 단위로 다뤄진다.
처음엔 이 부분이 의문이었는데, 당시 환경을 떠올리면 이유가 자연스럽게 보인다.
전 세계 언어를 모두 담아야 하는 상황에서 문자 크기가 계속 변하는 구조(UTF-8)보다는 일정한 폭을 가진 UTF-16이
운영체제 내부 동작과 API 구조에 잘 맞았기 때문이다.
UTF-16은 대부분의 일반 문자들이 2바이트 안에서 표현되기 때문에
문자 하나를 이동하거나 길이를 계산하는 과정이 단순했고, WinAPI를 바꿔야 할 필요도 크게 없었다.
이런 이유들 때문에 Windows 내부 구조는 지금도 UTF-16 기반으로 동작하고 있다.
A/W의 의미
문자 인코딩을 이해하고 나면 WinAPI가 ANSI와 WIDE 두 가지 버전을 제공하는 이유가 자연스럽게 이어진다.
Windows가 유니코드로 넘어가는 과정에서 기존 ANSI 기반 프로그램들과의 호환성까지
모두 끊지 않으려다 보니 A 버전과 W 버전을 함께 유지하게 된 것이다.
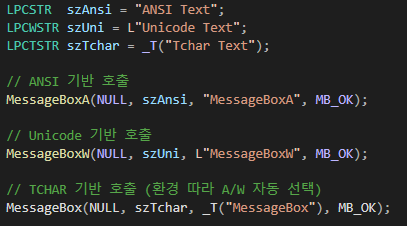 MessageBox 호출 예제
MessageBox 호출 예제
MessageBox만 봐도 구조가 바로 보인다.
- MessageBoxA → ANSI 기반
- MessageBoxW → 유니코드 기반
컴파일러의 문자 집합 설정에 따라 MessageBox라는 이름은 결국 둘 중 하나로 결정된다.
 Character Set
Character Set
멀티바이트 환경이라고 해도 전처리기 설정이 유니코드로 묶여 있다면 TCHAR 계열은 계속 wchar_t 기반으로 동작한다.
문자 집합을 바꿔도 원하는 구조가 바로 반영되지 않았던 이유가 여기에 있었다.
char, wchar_t, TCHAR
문자를 담는 자료형을 이해하면 A/W 구조가 훨씬 단순하게 보인다.
char는 1바이트 정수 값을 그대로 문자로 사용하고, wchar_t는 2바이트 또는 그 이상 크기로 유니코드 문자를 표현한다.
Windows에서는 wchar_t가 UTF-16과 맞물려 2바이트 구조를 사용한다.
TCHAR는 이 둘을 환경에 따라 자동으로 선택하는 타입이다.
UNICODE 환경이면 wchar_t로, 멀티바이트 환경이면 char로 매핑된다.
하나의 코드로 두 환경을 모두 커버할 수 있게 하려는 방식인듯하다.
LP
WinAPI 문서를 읽다 보면 LPSTR, LPWSTR 같은 자료형이 계속 등장한다.
한동안 이 표현이 낯설었는데, 자세히 알아보니 옛날 16비트 윈도우에서 사용 되었던거같다.
Near Pointer와 Long Pointer 라는 개념이 있었지만 지금 기준에서 보면 그냥 포인터라는 의미에 가깝다.
여기에 C가 붙으면 const가 붙은 읽기 전용 문자열이 된다.
ANSI / Unicode / TCHAR
 ANSI/Unicode/TCHAR
ANSI/Unicode/TCHAR
ANSI
LPSTR : char*
LPCSTR : const char*Unicode
LPWSTR : wchar_t*
LPCWSTR : const wchar_t*TCHAR
LPTSTR : char* 또는 wchar_t*
LPCTSTR : const char* 또는 const wchar_t*
마무리
프로젝트를 구성하거나 API를 공부하다보면 문자열 인코딩은 생각보다 많은 영향을 준다.
단순한 글자로만 보이던 문자열들이 운영체제 내부 구조와 API의 흐름까지 이어진다는 점이 보이기 시작하면
Win32를 다루는 방식이 훨씬 안정적으로 느껴진다.
이번에 글을 작성하며 느낀거지만 상대적으로 잊기 쉬워 보이는 내용이더라도 규칙만 생각하면
결코 쉽게 잊지 않을수 있다고 생각한다.